
前言
自Hot Chips开始专设AI硬件Session开始,九年时间,Hot Chips的主角从单芯片算力提升和架构创新,转向围绕计算/内存/互连/软件栈的系统化工程。本文将围绕四个关键观察梳理2017–2025数据中心AI芯片及基础设施的演化逻辑,力图帮助大家抓住关键趋势,思考未来方向。
Hot Chips 时间线
2017
Jeff Dean Keynote预测AI未来;TPU深度解读;英伟达Volta/V100引入Tensor Core。
2018
NVSwitch + DGX-2把16×V100组成单一高带宽域,单芯片竞争开始让位于系统扩展。
2019
AI DSA百花齐放,华为达芬奇亮相;Cerebras WSE 晶圆级AI芯片首秀;Intel NNP-T/NNP-I与Habana Gaudi代表“训练/推理解耦、以太路线”。
2020
英伟达A100引入TF32、结构化稀疏、MIG;谷歌公开TPU v2/v3设计细节;阿里含光与百度昆仑展示中国互联网公司造芯。
2021
DPU/IPU概念普及:英伟达BlueField系列推进“把基础设施税从CPU挪走”;Graphcore的片上大SRAM与BSP并行;SambaNova的CGRA+Dataflow。
2022
英伟达H100/Hopper加入FP8/Transformer Engine与TMA;Grace + NVLink-C2C 形成 CPU↔GPU 一致互连。其他厂商的多样化尝试,云顶4008集团BR100 GPU Chiplet、Groq TSP、Tesla Dojo从芯片到超级计算机。
2023
英伟达Bill Dally Keynote,总结AI芯片的发展;谷歌TPU v4公开OCS光路可重构网络,4096芯片可按需调整拓扑;系统思维成为主旋律。
2024
英伟达Blackwell/GB200,精度下沉到4bit,NVL36/NVL72 做成机架级NVLink域;OpenAI分享可扩展AI基建方法论;AMD MI300X把HBM容量推到192 GB;Sambanova升级多级内存;Tenstorrent基于Riscv构建统一架构AI芯片。
2025
“Rack as a Computer”进入实操年,多场教程与报告围绕Scale-up×Scale-out展开;定制芯片和CPO,应对Beachfront(Shoreline)IO扩展的挑战。
在进入正题之前,我们先看两个比较重要的Keynote:2017年谷歌Jeff Dean的“Recent Advances in Artificial Intelligence via Machine Learning and the Implications for Computer System Design”和2023年英伟达Bill Dally的“Hardware for Deep Learning”正好可以作为AI芯片故事的开篇和阶段性总结。
.png)
今天我们回看Jeff Dean在2017年的演讲,不得不佩服他对AI和硬件系统未来发展的精准预测。可以说AI芯片跌宕起伏的故事,正是以这个Keynote开场的。
时间到了2023年,Bill Dally总结了英伟达是如何在10年内把芯片性能提升1000倍的。(下图为2024年的一个演讲[1]里的更新版本,加入了Blackwell)。
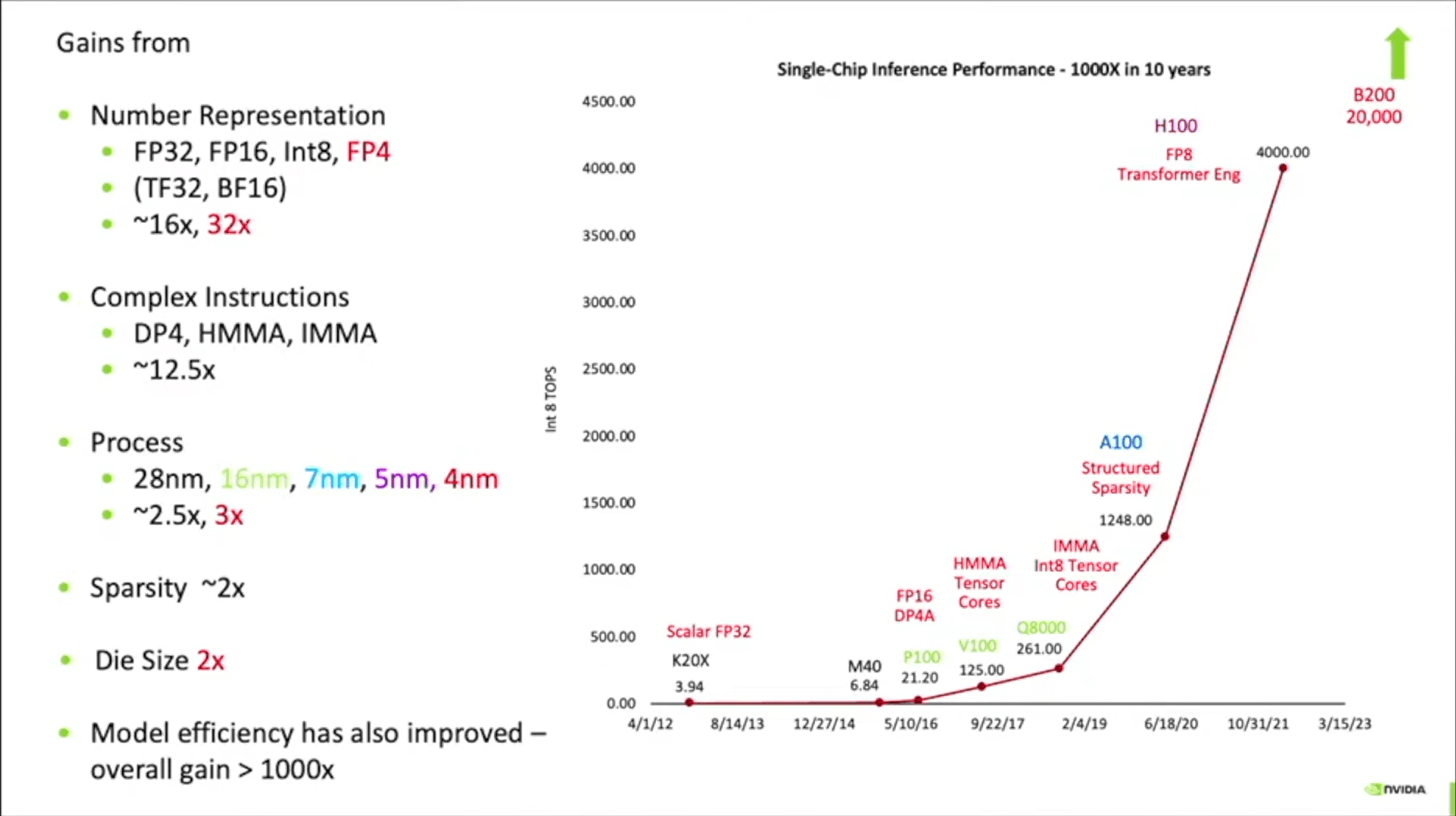
这里以Kepler架构为起点,硬件上最大的提升来自低精度计算,从最早的FP32,到Blackwell的FP4,提升32倍;定制复杂指令,主要是TensorCore执行的矩阵运算,提升了12.5倍左右。而工艺,结构化稀疏和封装则各自提升了2~3倍。从这里可以看出,英伟达GPU硬件性能的提升,主要来自针对AI计算特征的定制化设计(也可以说是在GPU架构中融入的大量的DSA设计)。这里正好引出我们想讨论的第一个话题。
NO.1
DSA还是GPU,不是非此即彼的竞争?
.png)
2017年的Hot Chips上微软的talk[2],展示了这张图,已经包括了大量初创公司和新的架构。当时的叙事是,GPU太通用,进行AI计算的效率太低,通过设计针对性的DSA可以大幅提高计算效率,这也是五花八门AI DSA爆发的原因。这之后的数年,这一名单还在不断增加,科技大厂自研芯片,如AWS的Trainium,微软的MAIA,特斯拉的Dojo;初创公司如Habana,Sambanova,Tenstorrent,直到今年Hot Chips上的d-Matrix。这些芯片都试图做出差异化的AI DSA架构以提高AI计算效率,成为AI算力的主流。下表总结了历届Hot Chips会议上展示的各种DSA架构创新。
2017|Wave Computing
Dataflow Processing Unit
创新:Dataflow + Clockless CGRA
2017|谷歌
TPU(Tensor Processing Unit)
创新:基于脉动阵列的大规模矩阵乘单元,面向推理的专用芯片
2018|MYTHIC
创新:基于Flash的模拟存内计算
2019|Cerebras
WSE(Wafer-Scale Engine)
创新:晶圆级单芯片 + 片上海量 SRAM + 片上网络,训练/推理的一体化近存架构
2019|英特尔 (Nervana)
NNP-T / NNP-I
创新:训练/推理解耦;以太网原生的线性扩展与 BF16 等训练数值格式
2019|Habana Labs
Gaudi / Goya
创新:TPC + GEMM + DMA 的异构内核;RoCE/以太网Scale-up的训练/推理方案
2019|华为
Ascend(达芬奇)
创新:CUBE张量阵列 + 大带宽片上存储层次;覆盖推理与训练SKU
2020|谷歌
TPU v2 / v3(设计细节)
创新:矩阵阵列/数据流微架构与指令通路公开;Pod 级系统化设计方法
2020|阿里巴巴
含光 800
创新:面向云端视觉/检索推理的 NPU;大容量片上存储 + PCIe 接入的服务化落地
2020|百度
昆仑(Kunlun)
创新:通用 AI 加速器 SoC 路线,兼顾推理/训练的产品化形态
2020|LIGHTMATTER
创新:硅光计算
2021|Graphcore
Colossus Mk2 IPU
创新:片上大规模分布式 SRAM + 细粒度 BSP/消息并行
2021|SambaNova
SN10 RDU
创新:CGRA + 数据流的可重构加速架构,编译期将计算映射为硬件流水
2022|Groq
TSP
创新:软件定义的“张量流”执行 + 生产者/消费者流水
2022|特斯拉
Dojo
创新:微架构基于Risc-V扩展,System-on-Wafer尝试,整机互联/散热/供电的系统性优化
2023|谷歌
TPU v4 + OCS
创新:光路可重构网络使 4096 芯片可按任务修改拓扑;引入SparseCore等面向推荐/Embedding
2023|三星
PIM HBM
创新:在HBM堆内叠入计算逻辑HBM2/3堆内PIM路线,以“存算耦合”减少跨封装搬运
2024|Meta
MTIA
创新:面向推荐推理的成本优化NPU,大量工程优化,强调TCO
2024|Tenstorrent
Blackhole + TT-Metal
创新:RISC-V 大/小核结合的通用可编程架构;GDDR外存 + 400G级以太扩展
2024|微软(Azure)
Maia 100
创新:6bit精度、以太网Scale-up、与Azure编程栈/服务深度集成
2025|谷歌
TPU “Ironwood”
创新:面向大规模推理的第七代TPU:更高HBM容量/带宽与更大Pod规模
2025|d-Matrix
Corsair / 3D-IMC
创新:3D Digital In-Memory Compute
上述这些新的尝试不乏创新的想法和巧妙的设计,但时至今日,我们并没有看到那个AI DSA芯片真正挑战了英伟达GPU的地位。
这背后主要有两个原因。首先,GPU的架构发展并没有停滞不前,不仅不断融入专门针对AI的DSA设计,甚至借助生态的优势还在一些方面(比如混合精度设计)走的更快。HC29(2017),英伟达在 Volta/V100的报告里深入讲解了Tensor Core,明确“深度学习是GPU的一等工作负载”。HC32(2020)的A100引入TF32和2:4结构化稀疏。HC34(2022)的H100/Hopper又加入FP8+Transformer Engine(TE)、TMA(Tensor Memory Accelerator)。HC2024的Blackwell/GB200再把低比特推进到FP4/FP6,并把“机架级NVLink域”(NVL36/NVL72)做成标准交付形态。这些专门针对AI场景的设计,让今天的GPU已经和2017年前的GPU完全不是一个“物种”了,在主要计算场景中的计算效率,完全不输专门定制的DSA。
另一方面,GPU渐进式的引入DSA设计,在提高计算效率的同时,尽可能保持了编程模型和软件生态的稳定性。反观大量AI DSA公司,由于软件生态的问题,其硬件架构上的创新完全无法在应用场景中落地,一直存在纸面性能无法兑现的问题。
当然,近几年AI芯片厂商和大厂自研芯片的尝试也都会把系统扩展能力和软件生态放在最重要的位置考虑。比如谷歌配合TPU做了大量系统扩展方面和软件生态的创新和探索,催生了OCS和大量AI编译器方面的工作。而LLM大模型出现之后,一些AI芯片厂商抓住大模型推理的差异化需求,充分发挥DSA的优势(低延时推理),同时通过MaaS模式解决软件生态上的短板。这些尝试也算是AI DSA的进化了。
整体来讲,DSA的本质是针对特定场景和工作负载的优化,和GPU的关系并非什么路线之争。大家最终的目的都是提高计算效率,降低计算成本,推动AI的进步和落地。
No.2
从单芯片竞速到系统化设计
今年的Hot Chips上,Day0的tutorial:Datacenter Racks,开篇的题目是“The Hot Chip is a Rack”,非常好的总结了这些年AI硬件的发展。

从2017年的TPU和Volta定义了AI芯片,单芯片的能力已经大幅提升(参见前面Bill Dally的图),后续的发展只能靠更大规模的扩展。
实际上,早在HC30(2018年),DGX-2+NVSwitch就走出了Scale-up的第一步,16×V100被连接成单一高带宽域,工程上第一次把“多卡像一张卡”变成可复制的商品化系统。会场上大家最关心的问题从“卡有多强”改成“域有多大、带宽如何配平、编译器怎么映射”。
四年后的HC34,Hopper把这个命题往纵深推进。报告不再只讲计算核、指令与缓存,而是把“核内搬运与并行原语”(例如TMA、thread-block cluster)和“节点/机内一致互连”(Grace–NVLink-C2C)与“机群级专用网络”(NVLink-Network Switch)一起打包。C2C解决CPU↔GPU的数据通道,再把GPU↔GPU做成一个“域”,再按照scale-up域和scale-out域去切分AI计算负载。机架内的NVL36/NVL72把GPU↔GPU通信做成一个“平面”,MoE的 all-to-all 和混合并行的集合通信因此能在域内高效执行;机架间靠IB/RoCE分层与拓扑感知路由/通信库的优化适应AI通信特征。
HC35的TPU v4则探索另一条路径:让“拓扑本身”可编排化,使用OCS光路交换在4096颗芯片的规模里按作业切换拓扑,避免“固定拓扑+多样作业”的错配,支持AI训练和推理的各种并行方式。到HC36–HC37,Scale-up和Scale-out成为Hot Chips的一条主线,NVL36/72把“机架级NVLink域”作为最小交付颗粒,液冷、供配电、交换背板、软件随机架出厂,与此同时还有大量“以太/光互连”的系统化方案。
2018|英伟达
NVSwitch+DGX-2:以NVSwitch将16×V100组成单一高带宽NVLink 域,确立“多卡像一张卡”的路线。
2021|英伟达
BlueField-3 DPU:将网络/存储/安全从CPU卸载到DPU+DOCA软件栈。
2022|英伟达:
NVLink-Network Switch:用专用交换芯片把NVLink从机内扩展到机间,构建数百GPU的低延迟通信域。
2022|英伟达
Grace+NVLink-C2C:C2C提供900GB/s级芯间一致互连,CPU/GPU统一寻址与带宽池化。
2022|特斯拉
DOJO:包括Keynote在内有三场讲演,介绍了从算法到芯片到系统的整体协同设计。
2023|谷歌
TPU v4+OCS:在单机房4096芯片规模内按作业重构多种拓扑。
2024|英伟达
GB200 NVL36/NVL72:将NVLink扩展为整机架统一互连域并配套液冷/供配电/背板,机架成为最小交付与调度单元。
2024|特斯拉
DOJO网络:An Exa-Scale Lossy AI Network using the Tesla Transport Protocol over Ethernet (TTPoE).
2024|Broadcom
CPO:以近包/共封装光引擎突破“封装海岸线”I/O 瓶颈,显著改善每比特能耗与端口密度。
2024|Tenstorrent
Blackhole + TT-Metal:芯片内外统一以太编程与 10×400 GbE 扩展,通过软件/路由/数据流把集群像单机调度。
2025|多方Tutorial
Datacenter Racks:系统讨论机架级架构、液冷、供配电与布线/光互连——“机架即计算机”进入实操。
2025|华为
UB-Mesh:数据中心内的多层互连抽象成一套“统一总线(Unified-Bus)”范式。
2025|谷歌
TPU “Ironwood”:单Pod扩展至9,216颗、1.77 PB共享HBM,继续以OCS+ICI组织超大规模内存与算力。
2025|英伟达
CPO交换机:披露1.6T级CPO光引擎与CPO交换机进展,提出跨数据中心“Scale-Across”概念。
这些报告汇成一句行业共识:硬件的设计粒度从单芯片并不断扩展,到server/rack/data center。芯片设计也不局限在计算芯片本身,而是必须考虑Scale-up与和Scale-out的方案,并合理分配资源。大家的目标与其说是让芯片更强,不如说是让系统更聪明。
No.3
“算力为王”让位于“内存为王、IO为王”,
封装/集成技术快速进步成为关键
文章开头我们看到的Bill Dally“十年千倍”曲线,其实是在把工程账单摊开:最大一部分收益来自数值系统(从FP32下探到FP8、再到Blackwell时代的FP4/FP6)和张量/矩阵类复杂指令;工艺、结构化稀疏与芯片面积提供的是2–3倍的提升。换句话说,纯算术的单位成本在快速下降。
与此同时,AI,尤其是大模型除了对计算的需求外,对参数、KV-cache、激活张量的存储和搬移提出了数量级更高的要求:当“算术越来越便宜”,内存与互连的挑战就更为突出。这一“重心转移”在近几届Hot Chips上非常直观。
先看内存:MI300X把单卡HBM推到192 GB、5 TB/s+,把“少卡装大模、长上下文推理”作为芯片关键卖点;SambaNova强调“多级内存/数据摆放”,把热数据尽量留在离计算更近带宽更大的内存上(SRAM/HBM),把冷数据外放到容量更大更便宜的DRAM上,并用编译器与运行时完成“静态/动态混合”的搬运。互连层面,近几年的趋势是一边在电互连上把“域”做厚(“能用铜的地方尽量用铜”),一边在光互连上把“边界”外推。
要支撑这场迁移,封装/集成技术是关键基础;反过来,AI计算的巨大需求又大大推进了封装集成技术的进步和快速落地。
从HC34起,先进封装与芯粒互连几乎年年有专场/教程,讨论也越来越“工程化”。基本逻辑也非常简单,大单片逼近光罩与良率极限,于是Chiplet+2.5D/3D成为更合理的方案。TSMC 3DFabric(CoWoS/SoIC)把“大中介层+垂直直连”变成“封装级系统总线”,PDN、去耦与热路径前移到封装完成共设;UCIe在PHY→协议→一致性上推进“跨厂芯粒可拼装”,与NVLink-C2C/Infinity这类“垂直一致互连”长期并存。
HBM的发展也在加速,从2017年的HBM2,到最新的HBM4,不断提升的堆叠高度、通道与速率,甚至进一步扩展功能的custermised base die,同时也要求更强的封装电源网络、热扩散与翘曲控制。高密C2C(如NV-HBI)把“片上网络”的理念延伸为“封装级网络”,以数百GB/s乃至TB/s打通芯粒间缓存/一致性。在芯片的Beachfront(Shoreline) I/O越来越吃紧的情况下(如下图,来自[3]),CPO/近封装硅光的设计成为热点。
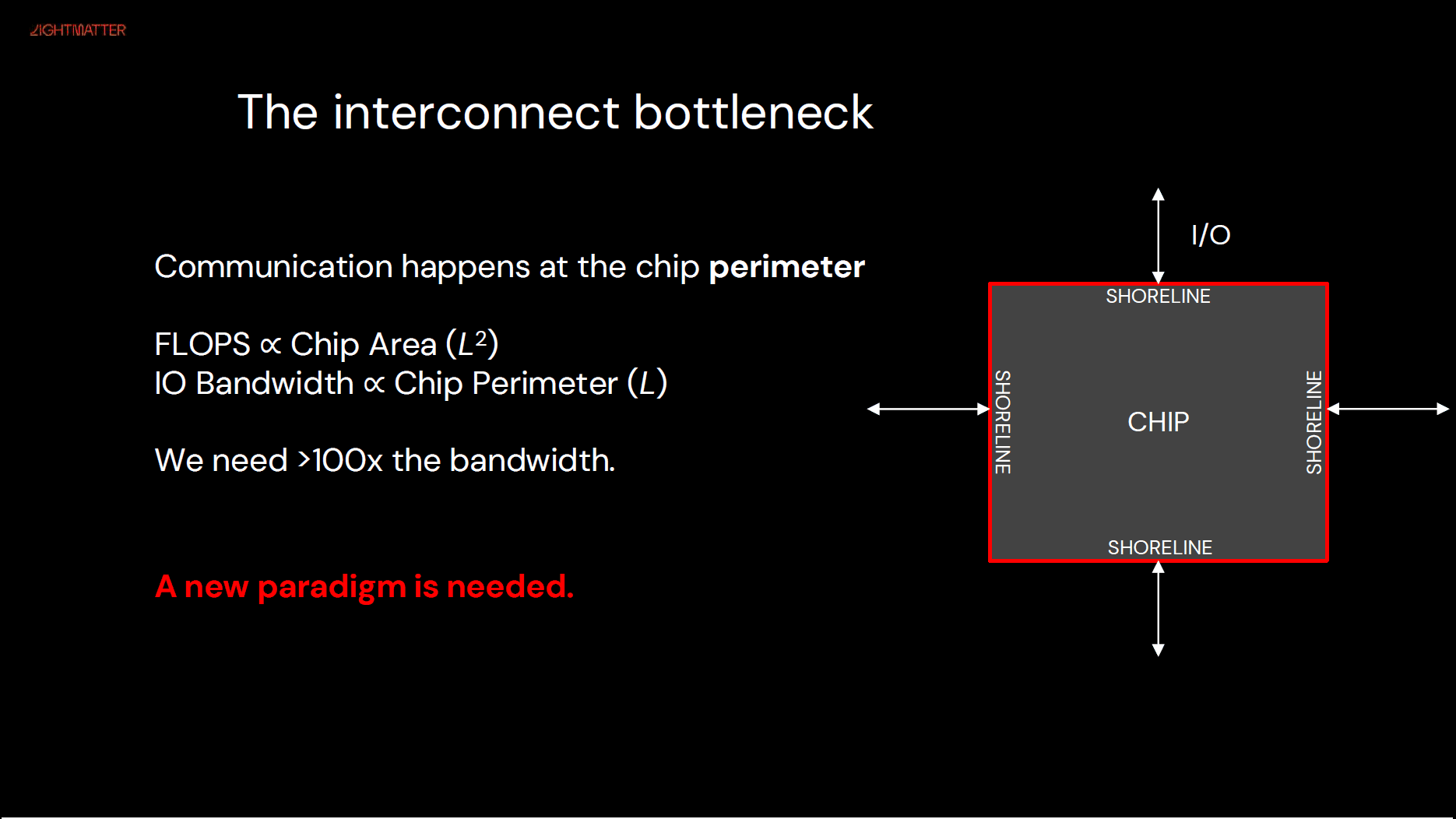
今年的Hot Chips,Optic专题中,利用CPO扩展Beachfront I/O成为重点,“实打实”讨论IO怎么扩、电-光转换与散热如何布置。当封装边缘的引脚密度与每比特能耗成为硬约束,把电-光转换前移到封装侧、用近封装硅光承接下一跳带宽,几乎成了继续拉高系统上限的必经之路。
除此之外,还要几种“极致可能性”的探索。典型的工作例如,Cerebras Wafer-Scale用“整片晶圆+片上网络 + 超大近存”把整个系统放进一个封装;Tesla Dojo把“芯片-板-系统”的封装与互连放到同一设计空间协同优化。
2019|Cerebras
WSE(晶圆级引擎):晶圆级集成(wafer-scale),在一整片晶圆上做“片上网络+海量SRAM”与冗余修复。
2020|特斯拉
Dojo:System-on-Wafer(SoW),计算/IO多裸片+RDL/供电/冷却一体化。
2021|多方Tutorial
Advanced Packaging:展示先进封装的技术进展和发展前景。
2022|英伟达
Grace ↔(C2C):Chip-to-Chip一致互连+2.5D。NVLink-C2C(一致互连)及与HBM/中介层的协同路径。在封装层把 CPU内存域与加速器显存域打通。
2023|多方Tutorial
UCIe:系统介绍UCIe(Universal Chiplet Interconnect Express)Chiplet互连标准。
2024|Broadcom
CPO:把光引擎贴近交换/计算ASIC(封装级上板光)。面向数Tb/s 级端口密度与更低 pJ/bit 的封装方案。正面突破封装海岸线(shoreline)IO限制,为机内/机架内光域铺路。
2024|AMD
MI300X:Chiplet+8×HBM3(192 GB)+大型中介层的平台化封装。
2025|Celestial
AI Photonic Fabric Module:in-die光I/O+CoWoS:把光口前移到芯片/桥片内部(非仅封装边缘),EAM取代微环、更强热稳健;释放“海岸线”,支持package-to-package光互连。
2025|Lightmatter
Passage M1000:3D光学中介层/光学插板:参考平台114 Tb/s,面向 >200 Tb/s XPU;256 光纤、1.5 kW+供电、内置固态光路交换。
2025|Ayar Labs
UCIe Optical I/O Chiplet / Retimer:UCIe光口芯粒(8 Tb/s 级):8 Tb/s、UCIe兼容、面向规模化AI的光I/O标品。
No.4
对场景和软件的关注
Hot Chips虽然是芯片厂商最重要的会议,但对场景和软件的关注度一点都不低。特别是从2017年AI浪潮开始,硬件和场景、软件的关系更为紧密,可以说完全融合在一起了。虽然会议的主要内容仍然是芯片,但很多Key Notes多来自AI应用的一线厂商,这些讲演的主要目的是从应用场景的角度对AI系统提出需求和关于算法和软硬件协同设计的思考。
此外,如果关注每届会议的Tutorial,就可以发现AI场景和软件栈占据了重要位置,反映了再软件框架,编程模型、语言、编译器等领域的最新工作。这些对于今天的AI芯片设计来说,也是必不可少的功课。
2017|Keynote 谷歌
Recent Advances in AI via ML and the Implications for Computer System Design
核心内容:从AI各种场景的最新进展,到AI和硬件系统的关系。
2020|Tutorial 多方
Machine Learning Scale Out
核心内容:Megatron Language Model;Distributed Parameter Server for Massive Recommender System;GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding.
2020|Keynote DeepMind
AI Research at Scale -Opportunities on the Road Ahead
核心内容:AI在RL,机器人等领域了最新进展,阐述AI发展和数据及算力的关系,提出对于硬件的思考,以及利用ML优化系统设计的可能性。
2021|Tutorial 多方
ML Performance and Real World Applications
核心内容:Modern Neural Networks and their Computational Characteristics、MLPerf™ Training and Inference、Software/hardware co-optimization on the IPU: An MLPerf™ case study、Deep Learning Inference Optimizations on CPUs、AI at Scale for the Modern Era、The Nature of Graph Neural Network Workloads、Challenges in large scale training of Giant models on large TPU machines、ZeRO-Infinity and DeepSpeed: Breaking the device Memory Wall for Extreme Scale Deep Learning.
2022|Tutorial 多方
Heterogeneous Compilation in MLIR
核心内容:综合介绍MLIR编译器框架以及相关项目,如CIRCT项目。
2023|Tutorial 多方
ML Inference
核心内容:推理栈专题包括量化、稀疏、kernel 设计、吞吐-时延、约束与端到端评估方法、PyTorch 2.0。
2023|Keynote 谷歌
Exciting Directions for ML Models and the Implications for Computing Hardware
核心内容:介绍AI最新进展,特别是规模化趋势,再次提出应该聚焦systems goodput而非芯片的“纸面性能”。
2024|Keynote Open AI
Predictable Scaling and Infrastructure
核心内容:再次阐述可预测Scaling(智能和计算量的相关性);讨论系统设计方法论:供电/冷却/网络/调度与SLO,把运营与成本纳入AI软件栈设计。
2025|Keynote DeepMind
Predictions for the Next Phase of AI
核心内容:LLM 需求清单(训练/推理/测试时扩展):“AI要什么?”硬件与软件栈职责。
2025|Tutorial 多方
Kernel Programming(Domain-Specific Languages & LLM-authored Kernels)
核心内容:Triton DSL 与自动内核生成:把编译/生成/验证 流水线化,提升 AI 软件栈生产力;GPU/TPU的kernel编程优化方法。
我们来看看今年Hot Chips上谷歌Noam Shazeer的Keynote。LLM对硬件的需求,简单粗暴,计算、内存、网络,什么都要。目前AI大模型的发展,从pre-training的scaling,到post-training和test time scaling,加上RL方法和Agent应用对于计算的需求,确实也是“既要也要”。

下一个1000x来自哪里
那么问题来了,“下一个1000×”会从哪里来?正好关注到Hot Interconnects上谷歌的Keynote[4]有这样一页Slides。

“Scale up → Scale out → Sustainable specialization”,这个回答似乎有点“抽象”,但也确实言之有理。
纵观Hot Chips这九年的历史,趋势也挺明确的:AI芯片的“单芯片算力增量”正由“封装×内存×互连”的系统增量接棒。至于“下一个1000×”会从哪里来?虽然大的方向已经比较明确,但系统级扩展的难度和成本也越来越高。要获得下一个1000x,我们还需要更多突破,通过3D堆叠提高内存的容量和带宽?通过WaferScale封装和集成把一个rack的算力装进“一颗芯片”?通过光互连彻底打破IO的束缚?这些技术都还在探索之中。另一个角度,是不是AI的计算范式又会随着RL/Agent的需求发生变化,利用新的DSA设计可能大幅提升计算效率?
在AI巨大需求的推动下,我们已经看到很多技术方向的探索和落地都有加速的趋势,期待这些技术的发展将会让下一个1000x尽快成为现实。
参考文献
[1]. Bill Dally, "Deep Learning Hardware: Past, Present, and Future", https://cra.org/wp-content/uploads/2024/08/Deep-Learning-Hardware-Session-Slides.pdf
[2]. Eric Chung & Jeremy Fowers, "Accelerating Persistent Neural Networks at Datacenter Scale", HC29 (2017)
[3]. Darius Bunandar, Lightmatter, "Passage M1000: 3D photonic interposer for AI",HC2025
[4]. Amin Vahdat (Google) "Now in Focus: the Fifth, GenAI Epoch of Computing Infrastructure ", HotI 2025
[5]. 本文内容均来自历年Hot Chips公开资料,https://hotchips.org/archives/